The Journey of Data Within a Global Data Sharing Initiative 🚀
A human story of collaboration, innovation, and the magic of federated data analysis.
What Happens When a Pandemic Pressures the World for Answers? 🌍
When COVID-19 hit, people everywhere—patients, clinicians, researchers—had one urgent question: What does this mean for people with multiple sclerosis (MS)? Could their treatments put them at greater risk of severe outcomes? Could the disease itself worsen COVID-19’s effects?
But here’s the challenge: diseases like MS are rare, and the data needed to answer these questions was sparse, scattered across the globe, and locked in silos. On top of that, the pandemic left little time for traditional research pipelines. The pressure to deliver answers was immense, and the stakes couldn’t have been higher.
This is the story of how we tackled this global challenge, bringing together innovation, collaboration, and a way to connect the dots while respecting privacy and trust.

Figure 1: A streamlined view of the data management pipeline for the Global Data Sharing Initiative (GDSI).
The Challenge: A Puzzle With Missing Pieces 🧩
MS is a rare disease, which means the data we need to study it is limited, fragmented, and locked in healthcare systems worldwide. Researchers couldn’t just centralize the data due to privacy concerns, ethical regulations, and institutional policies. And with the pandemic raging, there was no time to wait for lengthy bureaucratic processes.
So, we had to ask ourselves: How can we make sense of all this data without compromising trust or privacy?
The Big Idea: A Hybrid Approach to Data Sharing 💡
To tackle this, we came up with a three-layer hybrid data acquisition architecture. The goal was to be inclusive—gathering as much data as possible while respecting the diverse policies and constraints of data custodians.
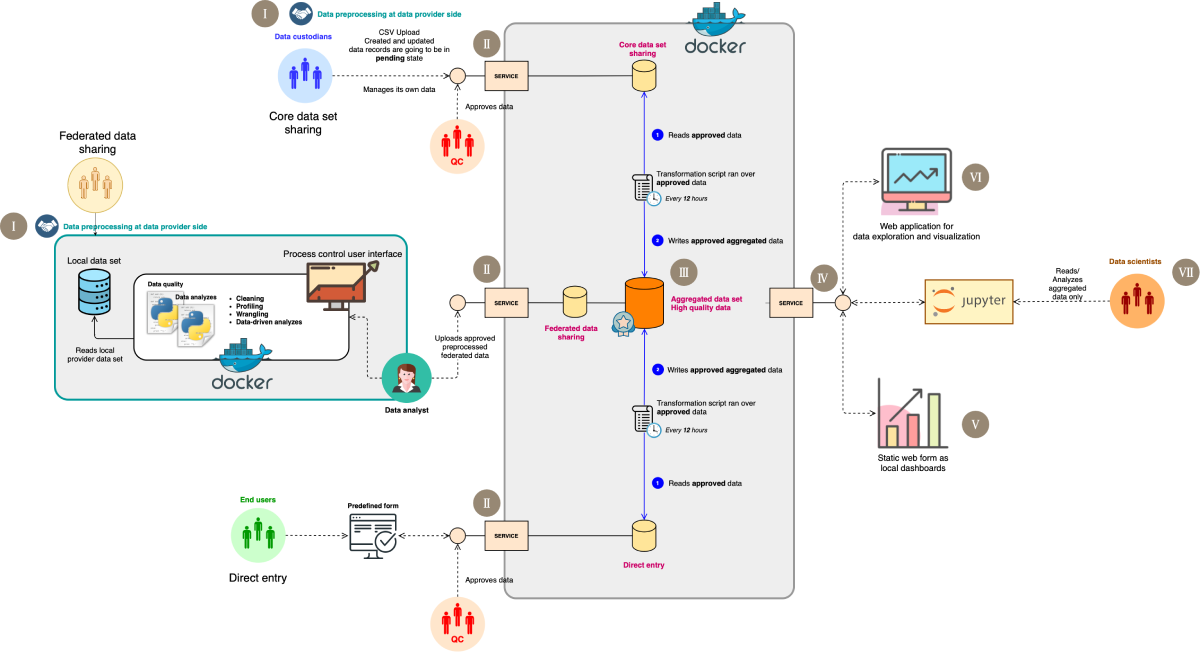
Figure 2: The global data sharing initiative’s end-to-end real-world data analysis pipeline. Step I illustrates the standardization process, which serves as the foundation of this architecture. In this phase, data custodians are requested to map their data to the “COVID-19 in multiple sclerosis core data set” (here referred to as the data dictionary). This process applies only to the core data set and federated model sharing registries, as direct entry is already embedded with a data dictionary via the web form. Step II involves the data acquisition pipeline, featuring distinct levels of data acquisition that depend on the data holder’s willingness and internal policies, all conducted in line with ethical and legal standards. Direct entry, core data set sharing, and federated model sharing constitute the 3 data stream levels. The first 2 levels interact directly with a central platform where the core dataset is shared as static files, in this instance, Comma Separated Values (CSV), whereas federated registries necessitate additional steps before submitting outcomes to the central platform. To incorporate federated registries into the pipeline, predefined queries are dispatched alongside Docker containers to the local side of the registries. The results of these containers are then shipped back to the central platform. In step III, data from different data holders are stored in separate layers to facilitate the next data integration process. Data integration, the subsequent step in the pipeline, entails consolidating data from distinct layers into a comprehensive data set. Step IV emphasizes the utilization of the integrated data set for further data exploration and analysis. Step V highlights the local dashboard, which serves as a quality check, enabling data providers to give feedback on their uploaded data as an additional sanity check. Step VI underscores the online dashboard that has been fed by the integrated data set, utilized by the taskforce during the development of the research questions to ascertain the feasibility of the study and to monitor the data being collected. In step VII, a Jupyter Notebook is provided to the data analysis team, securely connected to the integrated data set, facilitating statistical analysis.
Here’s why the hybrid approach mattered:
- It recognized that not all data holders could contribute in the same way.
- It provided multiple pathways to participation, making it easier for more stakeholders to join.
- It balanced inclusivity with privacy, ensuring no one-size-fits-all solution was forced on anyone.
The Three Layers of Data Sharing 🛠️
1️⃣ Direct Entry
Patients and clinicians could directly input data into secure, standardized web-based forms. This was ideal for collecting real-time information quickly and easily. 📝
2️⃣ Core Data Set Sharing
Institutions with pre-approved datasets could share their anonymized data directly with a central platform. This ensured high-quality data while maintaining privacy and regulatory compliance. 🔄
3️⃣ Federated Model Sharing
For institutions with stricter data-sharing policies, this was the game-changer. Instead of transferring sensitive data, we sent analysis scripts (using tools like Docker) to their servers. These scripts ran locally, created aggregated results, and sent them back for central analysis. This way, institutions participated without ever exposing raw data. 🧠
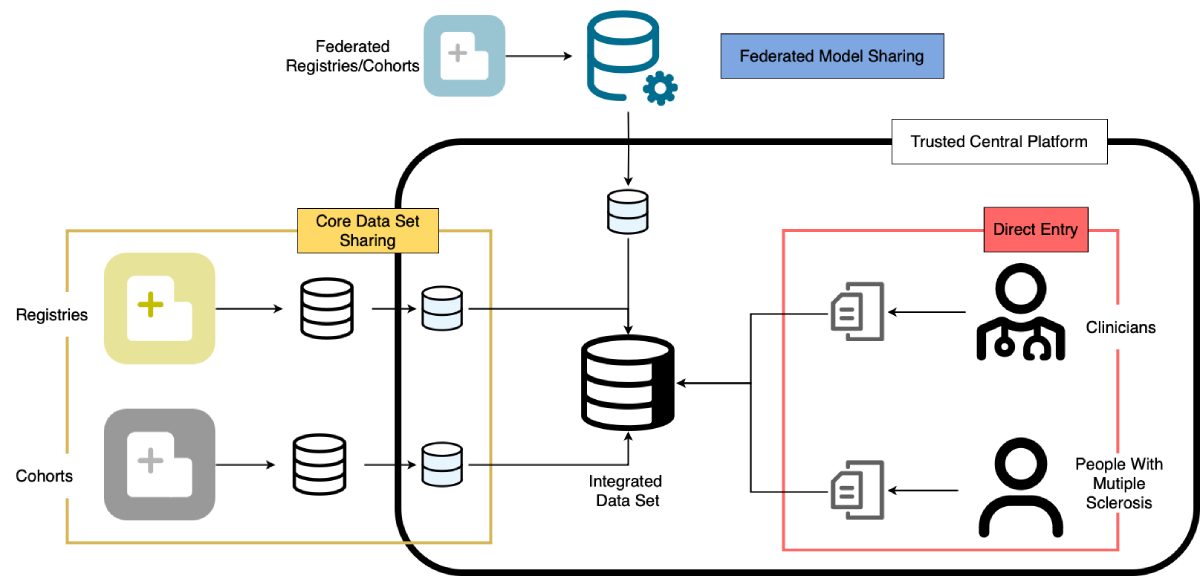
Figure 3: The global data sharing initiative data streams detailing the initiative’s inclusive approach through a hybrid 3-layer data acquisition architecture: (1) direct entry, where individuals upload their data via a web-based form; (2) core data set sharing, where registries upload patient-level data to the central platform under signed data transfer agreements and ethics approvals; and (3) federated model sharing, allowing registries with restrictive policies to participate without directly submitting patient-level data to the central platform.
Challenges Along the Way 🚧
Building this system wasn’t without hurdles:
- Data Formats: The diversity of data sources was like trying to fit pieces from entirely different puzzles together. Our solution? A standardized
data dictionaryto harmonize everything. - Privacy Awareness (Not Perfect Privacy): Federated analysis wasn’t inherently privacy-preserving. It operated in a controlled environment with a level of trust among participants. We made no assumptions of malicious or adversarial users, which kept the system simple and effective in this specific context.
- Global Coordination: With contributors from over 80 countries, aligning everyone’s efforts required open communication and mutual trust.
The Results: Insights That Matter 🌍
Thanks to this hybrid approach, we achieved remarkable results:
- Built the Largest Dataset: Data from thousands of MS patients with COVID-19 across 80+ countries.
- Identified Key Trends: For example, therapies like
rituximabandocrelizumabwere linked to higher risks of severe COVID-19 outcomes. - Informed Global Guidelines: These findings helped shape treatment recommendations and protect vulnerable patients during the pandemic.
Why This Matters 🌟
This project wasn’t just about MS or COVID-19—it’s a blueprint for future health data challenges. Whether it’s cancer, rare diseases, or mental health, this inclusive, hybrid system can help researchers collaborate globally without compromising trust or privacy.
It’s a glimpse into the future of healthcare, where stakeholders from diverse fields work together to make better, faster decisions that save lives.
Final Thoughts ❤️
This journey wouldn’t have been possible without the incredible collaboration of researchers, clinicians, and organizations worldwide. It’s a testament to the power of stakeholders coming together—when diverse voices join forces, even the toughest problems can be solved.
Here’s to more collaboration, more innovation, and a healthier future for all. 💪